Llama3가 더 강력한 모습으로 돌아왔다. Llama2가 발표된지 거의 9개월만이다. Meta는 먼저 Llama3 8B, 70B을 공개하였으며, 최대 400B급 Llama3 모델을 학습하고 있다고 한다. 최근 공개된 Llama3의 모델 성능과 주요 변화에 대해 알아보자.
Llama 3의 성능
Llama3는 이전 세대인 Llama2에 비해 모든 벤치마크에서 대폭적인 도약을 이루었다.
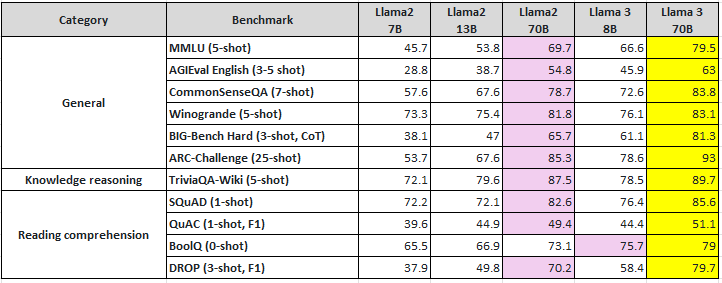
Base pretrained models (Llama2 vs Llama3)
- Llama3 70B: 모든 모델 벤치마크에서 Llama3 70B의 성능을 능가한다.
- Llama3 8B: 모든 모델 벤치마크에서 Llama2 7B, 13B보다 더 우수한 성능을 보인다. BoolQ 벤치마크의 경우, Llama3 8B이 Llama2 70B보다 더 우수한 성능을 나타낸다.
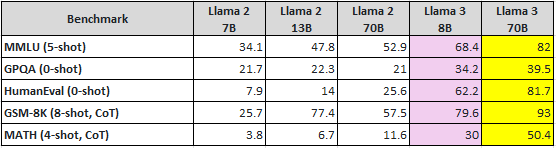
Instruct tuned models (Llama2 vs Llama3)
- Instruct tuned model들을 대상으로 벤치마크한 결과, Llama3 70B는 물론 Llama3 8B는 Llama2 70B보다 대폭 향상된 성능을 보이고 있다.
Instruct model performance (LLama3 vs Gemma 7B vs Mistral 7B Instruct vs Gemini Pro 1.5 vs Claude 3 Sonnet)
- Llama3 70B은 MMLU, HumanEval, GSM-8K와 같은 벤치마크에서 상용 모델인 Gemini Pro 1.5와 Claude 3 Sonnet를 능가하는 결과를 보여준다.

Meta Llama 3 Instruct Human evaluation
Meta는 Llama3 개발과정에서 표준 벤치마크에서 모델 성능을 살펴보고 실제 시나리오에 맞게 성능을 최적화하고자 새로운 고품질 인간 평가셋을 개발하였다. 이 평가 셋은 1) 조언 구하기, 2) 브레인스토밍, 3) 분류, 4) 비공개 질문 답변, 5) 코딩, 6) 창의적 글쓰기, 7) 추출, 8) 캐릭터에 빙의, 9) 공개 질문 답변, 10) 추론 11) 재작성, 12) 요약 등 12가지 주요 사용 사례를 포괄하는 1800개의 프롬프트를 포함한다.
아래 그림은 이 평가 세트를 기반으로 인간 annotator들의 선호도를 경쟁 모델과 비교한 결과이다. 이 결과를 통해 인간 annotator들이 경쟁 모델인 Claude Sonnet, Mistral Medium, GPT-3.5보다 Llama 3 70B Instruct 모델의 답변을 더 선호하는 것을 알 수 있다.

학습 데이터
Meta는 Llama3의 성능을 향상시키기 위해 Llama2에 비해 학습 데이터셋의 크기를 대폭 증가시켰으며 고품질의 데이터셋으로 학습하기 위해 데이터 필터링 파이프라인을 개발하였다.
학습 데이터셋의 크기
- Llama2(2T) → Llama3(15T) : Meta는 공개적으로 사용 가능한 소스에서 수집된 15T 개 이상의 토큰을 사용하여 Llama3를 pre-training하였다. 또한 Llama2 대비 7배 더 크고 4배 더 많은 코드를 포함하였다.
- Fine-tuning용 데이터셋으로 공개적으로 사용 가능한 명령 데이터셋과 사람이 주석을 추가한 10M 이상의 예제를 사용하였다.
- Meta는 pre-training/fine-tuning용 데이터셋에 Meta의 사용자 데이터를 사용하지 않았다.
다국어 데이터셋
- Llama3 pre-training 데이터셋 중 5% 이상을 30개 이상의 고품질 non-English 데이터셋으로 구성하였다.
- 하지만 non-English 성능이 영어와 같은 수준은 아니다.
데이터 신선도(Data Freshness)
- Llama3 8B 버전은 2023년 3월, Llama3 70B 버전은 2023년 12월을 기준으로 pre-training 데이터셋을 cut-off하였다.
데이터 필터링 파이프라인
- Meta는 Llama3를 최고 품질의 데이터로 학습하기 위해 일련의 데이터 필터링 파이프라인을 개발하였다.
- 데이터 품질을 예측하기 위해 이 파이프라인은 휴리스틱 필터, NSFW 필터, 시맨틱 중복 제거, 텍스트 분류기를 포함한다.
- Llama2가 고품질 데이터를 식별하는데 능숙하다는 사실을 발견하여 Llama2를 사용하여 Llama3를 위한 텍스트 품질 분류기의 학습데이터를 생성하였다.
Pre-training 시 scaling law 개발
Meta는 downstream 벤치마크 평가를 위해 일련의 scaling law을 개발하였다. 이 scaling law를 통해 모델을 실제로 학습하기 전에 주요 task(e.g. HumanEval 벤치마크)에 대해 가장 큰 모델의 성능을 예측할 수 있었다.
새로운 관찰 결과
Meta는 Llama3 개발 시 scaling law에 대한 새로운 사실을 관찰하였다.
- Chinchilla-optimal에 따라 8B 모델의 최적 학습 토큰양은 약 200B 개지만, 200B보다 더 많은 토큰을 학습하였을 때 모델 성능은 계속 증가한다.
- Llama3 8B, 70B를 최대 15T 토큰으로 학습하였을 때 모델 성능 로그 선형적으로 계속 개선되었다.
필자의 생각: Chinchila optimal보다 75배 넘게 학습하였음에 도 불구하고 모델 성능이 계속 개선되며 여전히 수렴점에 근접하지 않았다는 사실은 SLM(Small Language Model)의 가능성을 보여준다. Llama3의 관찰 결과를 토대로 향후 출시 되는 SLM들 또한 chinchila optimal을 뛰어넘는 대규모 데이터셋을 학습하는 방향으로 갈 것으로 예측된다. 더 오랫동안 학습된 SLM은 뛰어난 성능은 물론 더 적은 리소스로 추론할 수 있는 장점이 갖는다.
학습 Infrastructure
GPU 클러스터
- Llama3는 2개의 맞춤형 24K GPU 클러스터에서 학습되었다.
- 16K GPU에서 학습하였을 때 compute utilization 측면에서 가장 효율적인 400 TFLOPS/GPU를 달성하였다. (즉, H100의 FP16 성능이 990 TFLOPS임을 감안하였을 때 GPU utilization=40%를 달성하였다.)
- Meta는 학습 시스템과 학습 SW stack을 개선하여 Llama2 대비 Llama3의 학습 효율성을 최대 3배 증가시켰다.
Torchtune
- LLM을 쉽게 작성하고 finetuning하며 실험할 수 있는 새로운 pytorch 네이티브 라이브러리인 torchtune로 Llama3를 공동 개발하였다.
- Torchtune 은 전부 pytorch로 작성되었으며 메모리 효율적이고 해킹 가능한 학습 레시피를 제공한다.
모델 아키텍처
Llama2와 비교하여 Llama3는 큰 변화는 없었다.
GQA(Grouped Query Attention)
- Llama3 8B, 70B에 GQA를 적용: GQA는 모델 성능을 유지하면서 KV cache를 줄이는 방법이다. Llama2는 7B, 13B 버전에는 MHA(Multi-Head Attention)를 사용, 34B, 70B 버전에만 GQA를 사용하였다. Llama3는 추론 효율성을 개선하기 위해 가장 작은 8B 버전에도 GQA를 적용하였다.
새로운 Tokenizer
- Llama2(32K) → Llama3(128K): 토큰이 많아지면 시퀀스 길이를 더 압축할 수 있으며 더 나은 downstream 성능을 보인다.
- 벤치마크에 따르면 새로운 Tokenizer는 향상된 토큰 효율성을 제공하며 Llama2 대비 최대 15% 더 적은 토큰을 생성한다.
- Llama3 8B에 GQA와 새로운 Tokenizer를 적용하여 Llama3 8B는 Llama2 7B보다 더 많은 파라미터를 가졌음에도 불구하고 Llama2 7B와 동일한 추론 효율을 유지하였다.
Sequence Length
- Llama2(4K) → Llama3(8K): Llama2에 비해 sequence length가 2배 증가하였지만 최신 LLM(GPT-4. 128K)에 비해 여전히 작은 수준이다.
Llama3로 구축된 Meta AI
Llama3를 기반으로 구축된 Meta AI는 학습, 업무 처리, 컨텐츠 제작에 활용될 수 있다. 사용자는 사용 중인 앱에서 나가지 않고도 여러 앱(e.g. 피드, 채팅, 검색 등)에서 Meta AI를 사용하여 작업을 완료하고 실시간 정보에 액세스할 수 있다. Llama3를 탑재한 Meta AI는 facebook, Instagram, WhatsApp, Messenger, 웹에서만 사용될 수 있으나 Ray-Ban Meta 스마트 안경에서도 사용할 수 있으며 곧 Meta Quest에도 적용 예정이다.
Example #1 : Meta AI에 도움받기
- “@Meta AI find a picnic spot with a sunset view in San Francisco”
- “Where can I see cherry booms in Japan?
- “Next eclipse”
- “Calmest dog breeds for small apartment”
- “I’m studying for a college level biology exam focused on human gentics. Explain how hereditary traits work in simple language with examples.”
Example #2: Facebook, Instagram, WhatsApp, Messenger에서 Meta AI를 이용한 원활한 검색 통합
- “Recipes for homeade dressing” -> “Show me a video of the recipes”
Example #3: Facebook feed에서 Meta AI에 접근하기
- “Learn jazz chords”
Example #4: Meta AI의 Image 기능
- “Image a soccer game on Mars”
- “Image a bird” -> “Animate”
Llama3의 향후 계획
Meta는 이번에 출시된 Llama3 8B, 70B 보다 휠씬 더 큰 Llama3 400B을 학습 중이다. 현재 학습 중인 Llama3 400B의 초기 체크포인트(2024.04.15 기준)의 성능은 GPT4-turbo보다 더 우수하다. 최종 Llama3 400B의 성능은 GPT4-turbo를 뛰어 넘을 것으로 기대되며 오픈소스 모델이 상용 모델보다 더 뛰어난 성능을 내는 최초의 사례가 될 것으로 예측된다.
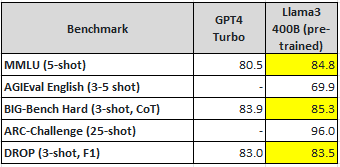
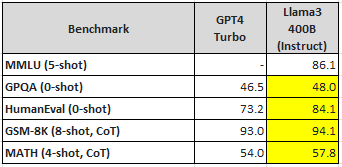
Meta는 다음과 같은 새로운 기능을 갖춘 여러 Llama3 모델을 출시할 예정이다.
- Multi-modality
- 여러 언어로 대화할 수 있는 기능
- 훨씬 더 긴 context window
- 전체적으로 더 강력한 능력
'서비스 개발' 카테고리의 다른 글
| [AWS] 다른 개인이나 비즈니스로 AWS 계정을 이전 (2) | 2024.04.27 |
|---|---|
| [AWS] 클라우드 컴퓨팅의 6가지 장점 (0) | 2024.04.27 |
| [JAVA] text/event-stream 받는 방법 (0) | 2024.04.27 |
| [AI] LLAMA 3 - 고성능 GPU 없이 실행하기 (0) | 2024.04.22 |
| [App] AI Town Project (0) | 2024.04.21 |